



News
Daltix introduces it’s Data Quality Indicators to ensure data transparency
If your data provider doesn’t give you a clear outline of how they test their own data for quality, you should get suspicious. In order to deliver data you can trust, we’ve developed the Daltix Data Quality Indicators. Read about what our DQIs are and why it’s good for your data here!

Location data
Download the Daltix Summary & Data Span Matrix
As we are expanding across Europe, here is a downloadable matrix on what data and features Daltix offers as well as what countries we collect in and for what retailers.

News
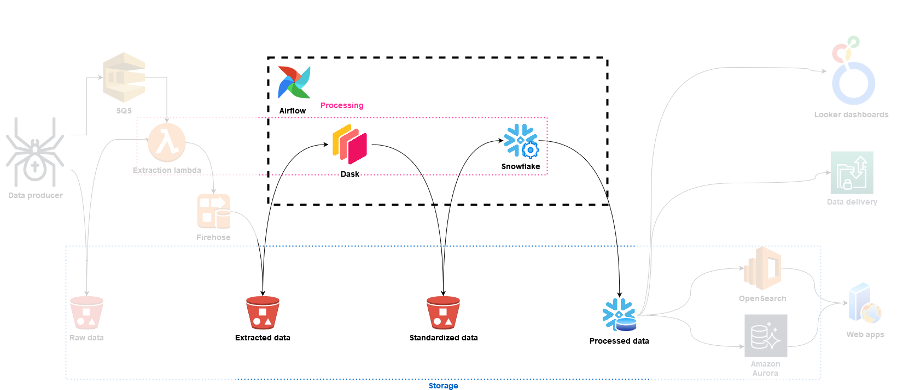
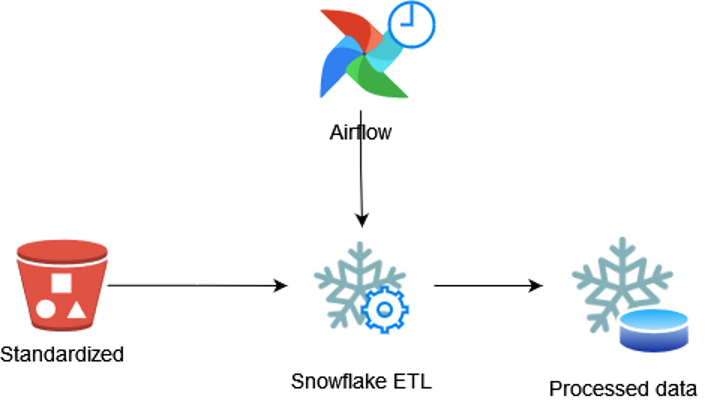
Daltix Data Architecture: Data Access
In the final blog post of the data architecture series, we’ll take a look at how Daltix can provide everyone who requires their data access in a way that suits them. To answer that, we’ll examine our two data setups and explain our experiences and how they fit into our data architecture.